
YouTube's famous Rob the Robot has over four hundred thousand subscribers. This YouTube page is famous for its learning content for kids. However, the artificial intelligence system behind the auto-generated captions of such content can use adult language by mishearing the correct word and replacing it with an inappropriate word that sounds similar to the original one.
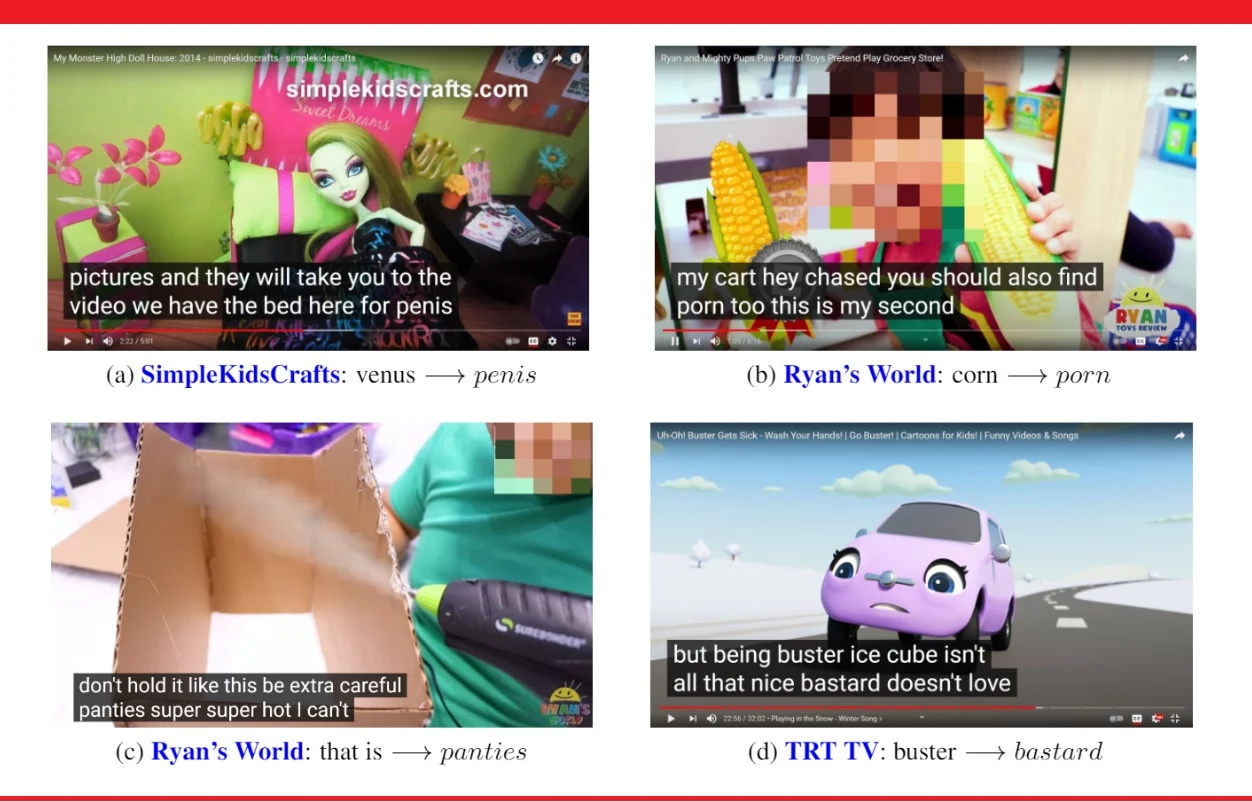
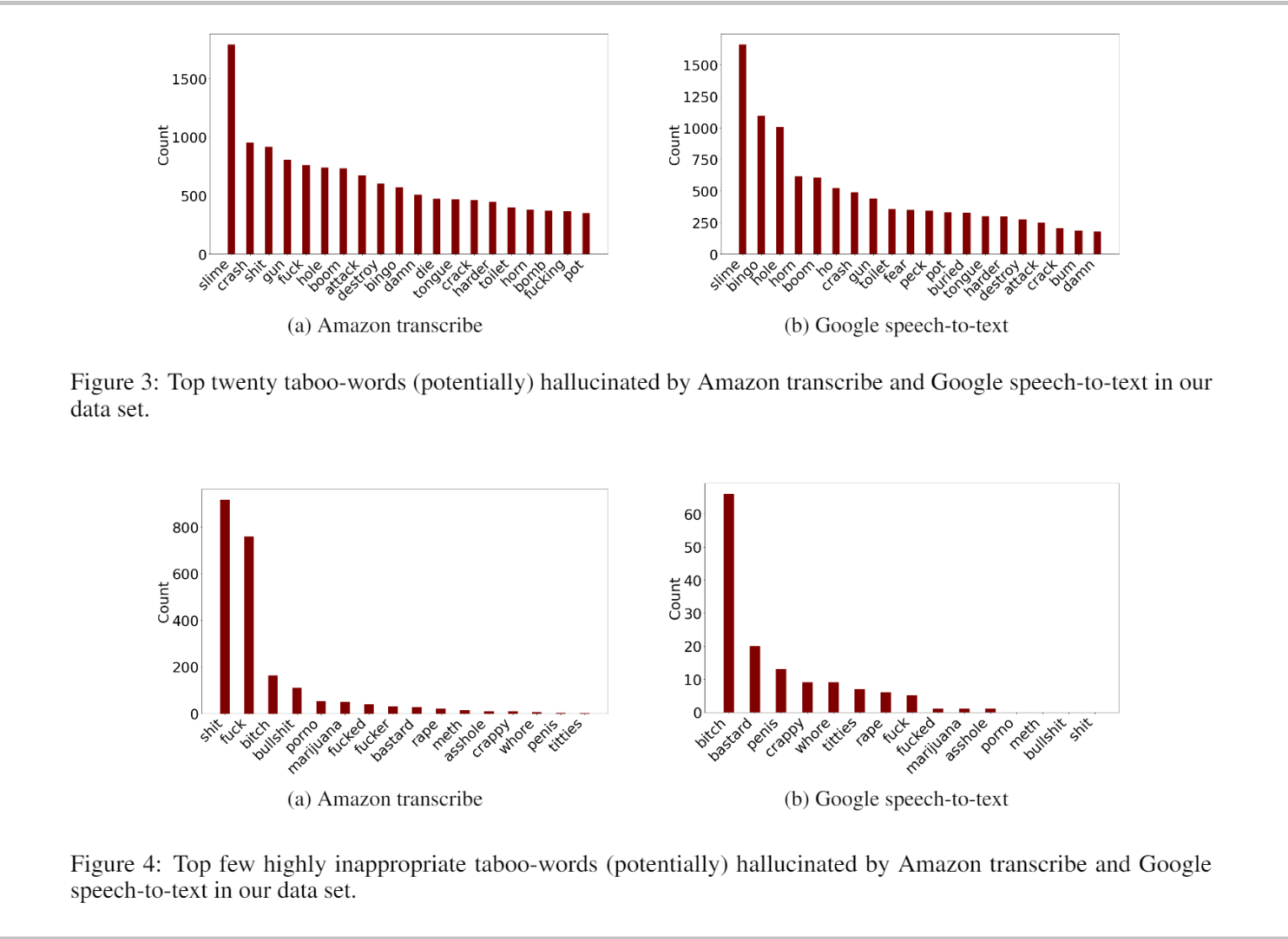
This study, which conducted recently, demonstrated that an AI algorithm can convert a children's educational video into nasty adult-language content. While carrying out research on this matter, over seven thousand videos were studied, belonging to over 24 different children’s channels. The result showed that 40% of the content had over thirteen hundred taboo words, while others had very inappropriate vocabulary. Common examples include replacing crab with crap and buster with bastard.
Ashique KhudaBukhsh, an assistant professor at Rochester Institute, is one of the researchers behind this discovery. Ashique shared his remarks by referring to this issue as a disturbing one.
Despite having a YouTube Kids option, many parents prefer the actual application. In research carried out by the Pew Research Centre, the results showed that over 80 percent parents of children under the age of eleven allowed their kids to watch YouTube content, whereas over 50% of these children watch content on a daily basis.
Jessica Gibby, spokesperson for the application, has assured everyone that the platform is working to make captions a safe place for children. Confusing words with age-restricted words is not just limited to children’s content, but even with other content as well. A reporter once discovered that audio transcription software, Trint, once misunderstood the name Negar and replaced it with the inappropriate N word.
There are many gaps still left to be filled with speech to text. Relying completely on an algorithm to fill these gaps is not a wise choice as it can create unwanted issues. Such as the one faced by a startup after it was discovered that the system was transcribing inappropriate sexual content involving adolescence.
Every system needs to be fed with data. In many cases, the audio data is usually added by adults, whereas children don’t get to add data as much. And even if they do add files, then the accent is not native, which creates confusion.
Rachael Tatman, a linguist and co-author of this research, suggested tuning of captions could help reduce the errors, but it wouldn’t be an easy task.
Ashique KhudaBukhsh and his team have also been working on possible solutions to this situation. They ran some audio through other software as well, such as on Amazon, and discovered that it also had the same issue. The spokesperson for Amazon has allowed the app developers to look into this matter for possible solutions on how to filter the words accordingly with content.
Read next: YouTube is exploring new methods to combat misinformation
This study, which conducted recently, demonstrated that an AI algorithm can convert a children's educational video into nasty adult-language content. While carrying out research on this matter, over seven thousand videos were studied, belonging to over 24 different children’s channels. The result showed that 40% of the content had over thirteen hundred taboo words, while others had very inappropriate vocabulary. Common examples include replacing crab with crap and buster with bastard.
Ashique KhudaBukhsh, an assistant professor at Rochester Institute, is one of the researchers behind this discovery. Ashique shared his remarks by referring to this issue as a disturbing one.
Despite having a YouTube Kids option, many parents prefer the actual application. In research carried out by the Pew Research Centre, the results showed that over 80 percent parents of children under the age of eleven allowed their kids to watch YouTube content, whereas over 50% of these children watch content on a daily basis.
Jessica Gibby, spokesperson for the application, has assured everyone that the platform is working to make captions a safe place for children. Confusing words with age-restricted words is not just limited to children’s content, but even with other content as well. A reporter once discovered that audio transcription software, Trint, once misunderstood the name Negar and replaced it with the inappropriate N word.
There are many gaps still left to be filled with speech to text. Relying completely on an algorithm to fill these gaps is not a wise choice as it can create unwanted issues. Such as the one faced by a startup after it was discovered that the system was transcribing inappropriate sexual content involving adolescence.
Every system needs to be fed with data. In many cases, the audio data is usually added by adults, whereas children don’t get to add data as much. And even if they do add files, then the accent is not native, which creates confusion.
Rachael Tatman, a linguist and co-author of this research, suggested tuning of captions could help reduce the errors, but it wouldn’t be an easy task.
Ashique KhudaBukhsh and his team have also been working on possible solutions to this situation. They ran some audio through other software as well, such as on Amazon, and discovered that it also had the same issue. The spokesperson for Amazon has allowed the app developers to look into this matter for possible solutions on how to filter the words accordingly with content.
Read next: YouTube is exploring new methods to combat misinformation