
There are over 7,000 different languages in this world and 40% of them exist without any form of written component. While the unwritten ordeal is posing to be a huge problem for various forms of new AI learning translation systems, Meta has a surprise in store.
Most AI speech-text translators must transform words said verbally into a written format before the actual process of translation can begin. So as you can see, it’s a challenge for many modern AI tools. But Meta is definitely leading in this respect at the forefront.
The company is addressing the problem of language barriers thanks to its open-source AI translators. This is reportedly an integral component of its UST program that works to create speech-to-speech translation over time so Metaverse denizens may interact in a more easy manner.
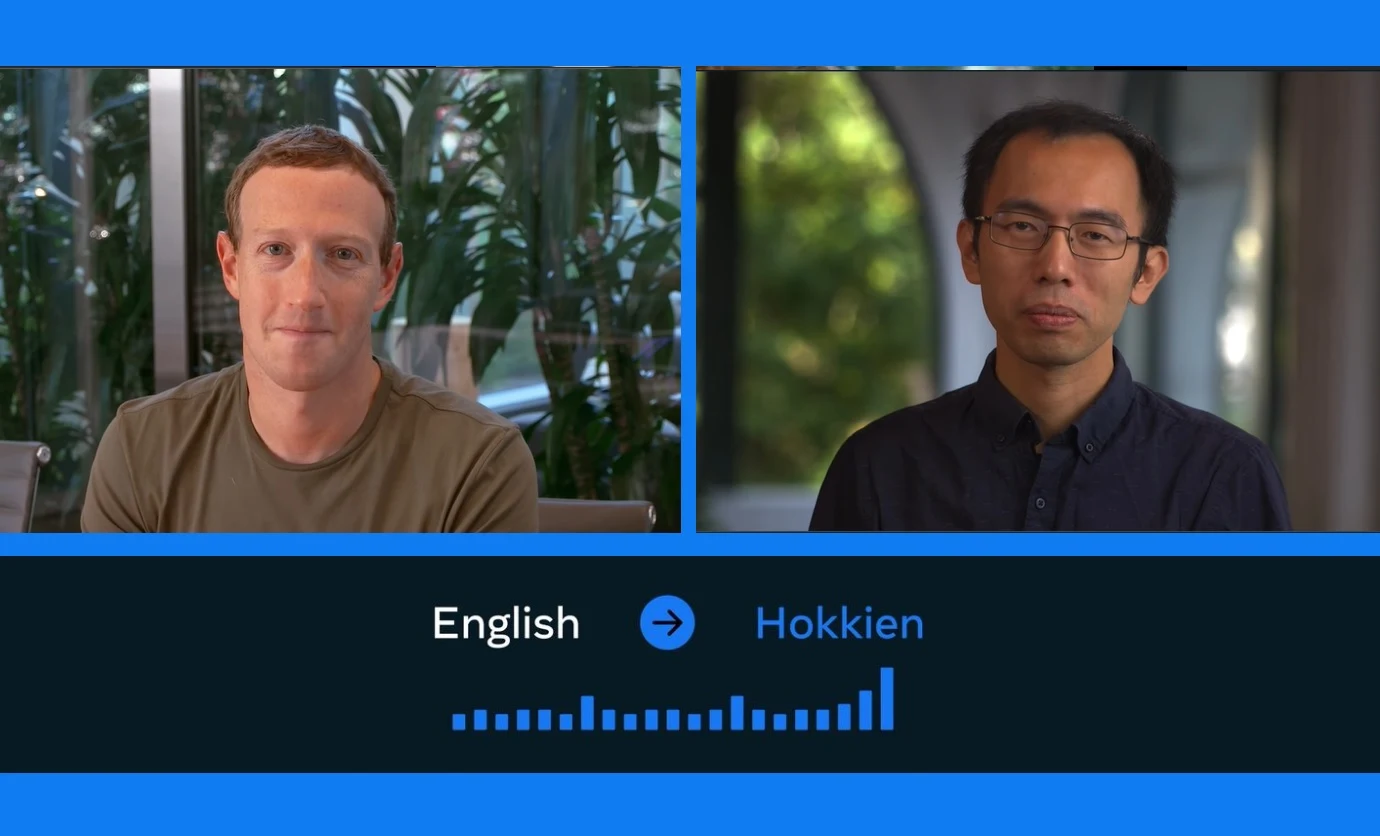
The news comes after the launch of the new research project that’s in its trial phase but has some promising results attached. Researchers that are a part of the study glanced over a language that is widely prevalent across Asia called Hokkien. It’s actually Taiwan’s main language.
And since Hokkien doesn’t have written forms, it was a challenge, to begin with. All machine learning tools require a lot of extensive examples were written and spoken variants must exist for the process of translation to begin.
So to overcome such an obstacle, Meta’s researchers made use of the Speech the Unit translation process. Here is where input speech was converted into a sequence of various acoustic units that are aligned on the path that Meta has pioneered.
As outlined by Meta CEO Mark Zuckerberg, the researchers were able to produce waveforms through such units. And a typical UnitY was seen being adopted for the two-pass decoding system when the term first-pass decoder was needed to produce text in a language that was relatable and similar. Here is where they used Mandarin, allowing the second pass decoder to make units.
Zuckerberg says Mandarin was chosen to create a pseudo label and that’s where English was first translated into Mandarin and then into Hokkien. After that, it was added to the training data.
So the system allowed people who spoke Hokkein to communicate better with those that spoke English. Yes, it’s a little time-consuming as each sentence continued to be translated in the form of a single sentence at any given time, but it was worth it as the results were being produced that couldn’t ever be done in the past.
With time, we don’t see why it can't apply to various other languages and may improve to one point that offers things like real-time translation.
In addition to all of this, we’re seeing Meta gain other open-sourcing details through this project. One such example is the new Speech Matrix feature that combines LASER which is Meta’s new data mining method with speech-speech translations.
As Meta’s CEO says, this particular system is going to make researchers produce speech-to-speech translation operating systems that are created by the company itself.
Read next: Meta’s Customer Complaints Agent Highlights The ‘Ugly Side’ Of The Job Including Death Threats, Insomnia, And More
Most AI speech-text translators must transform words said verbally into a written format before the actual process of translation can begin. So as you can see, it’s a challenge for many modern AI tools. But Meta is definitely leading in this respect at the forefront.
The company is addressing the problem of language barriers thanks to its open-source AI translators. This is reportedly an integral component of its UST program that works to create speech-to-speech translation over time so Metaverse denizens may interact in a more easy manner.

The news comes after the launch of the new research project that’s in its trial phase but has some promising results attached. Researchers that are a part of the study glanced over a language that is widely prevalent across Asia called Hokkien. It’s actually Taiwan’s main language.
And since Hokkien doesn’t have written forms, it was a challenge, to begin with. All machine learning tools require a lot of extensive examples were written and spoken variants must exist for the process of translation to begin.
We’re developing AI to help eliminate language barriers in the metaverse, so eventually you can talk to almost anyone with the help of real-time speech translations. 🗣️https://t.co/laNZKT7dV3 pic.twitter.com/SA2b6KfRpC
— Meta (@Meta) October 19, 2022
So to overcome such an obstacle, Meta’s researchers made use of the Speech the Unit translation process. Here is where input speech was converted into a sequence of various acoustic units that are aligned on the path that Meta has pioneered.
As outlined by Meta CEO Mark Zuckerberg, the researchers were able to produce waveforms through such units. And a typical UnitY was seen being adopted for the two-pass decoding system when the term first-pass decoder was needed to produce text in a language that was relatable and similar. Here is where they used Mandarin, allowing the second pass decoder to make units.
Zuckerberg says Mandarin was chosen to create a pseudo label and that’s where English was first translated into Mandarin and then into Hokkien. After that, it was added to the training data.
So the system allowed people who spoke Hokkein to communicate better with those that spoke English. Yes, it’s a little time-consuming as each sentence continued to be translated in the form of a single sentence at any given time, but it was worth it as the results were being produced that couldn’t ever be done in the past.
With time, we don’t see why it can't apply to various other languages and may improve to one point that offers things like real-time translation.
In addition to all of this, we’re seeing Meta gain other open-sourcing details through this project. One such example is the new Speech Matrix feature that combines LASER which is Meta’s new data mining method with speech-speech translations.
As Meta’s CEO says, this particular system is going to make researchers produce speech-to-speech translation operating systems that are created by the company itself.
Read next: Meta’s Customer Complaints Agent Highlights The ‘Ugly Side’ Of The Job Including Death Threats, Insomnia, And More
{kind=link}