
Internet is the most dynamic space available today with changes constantly taking place on it, resulting in updated versions of webpages and relegation of previous ones to obsoleteness. But those obsolete webpages do not lose their worth altogether. They could be required for varied reasons — to study the evolution of a website or gain access to an older version of a web page etc. — by different people and companies. For the same reason, those obsolete web pages are saved for any expected or unexpected future use on the Internet Archive known as the Wayback Machine .
A part of the Internet Archive, the Wayback Machine was introduced in 2001. Its main function is to save snapshots of webpages, so anyone interested can have access to previous versions of webpages of different websites. As of today, the Wayback Machine has over 916 billion web pages saved. In other words, people can access billions of these pages to see changes that occurred on websites over the years or to find a web page of a site at a specific time in its history.
Follow the Guide to Search/Find Older Version Of Web Pages on the Wayback Machine
1) Search Wayback Machine on Google and open the website or simply copy paste this URL or click on it https://web.archive.org/.

2) The search box is present on the front page. Enter the target url of the website whose previous versions of web pages you want to explore. Either use a domain name or the url of a specific page. For example, we are using https://www.wwe.com/ to explore how it appeared in the past.
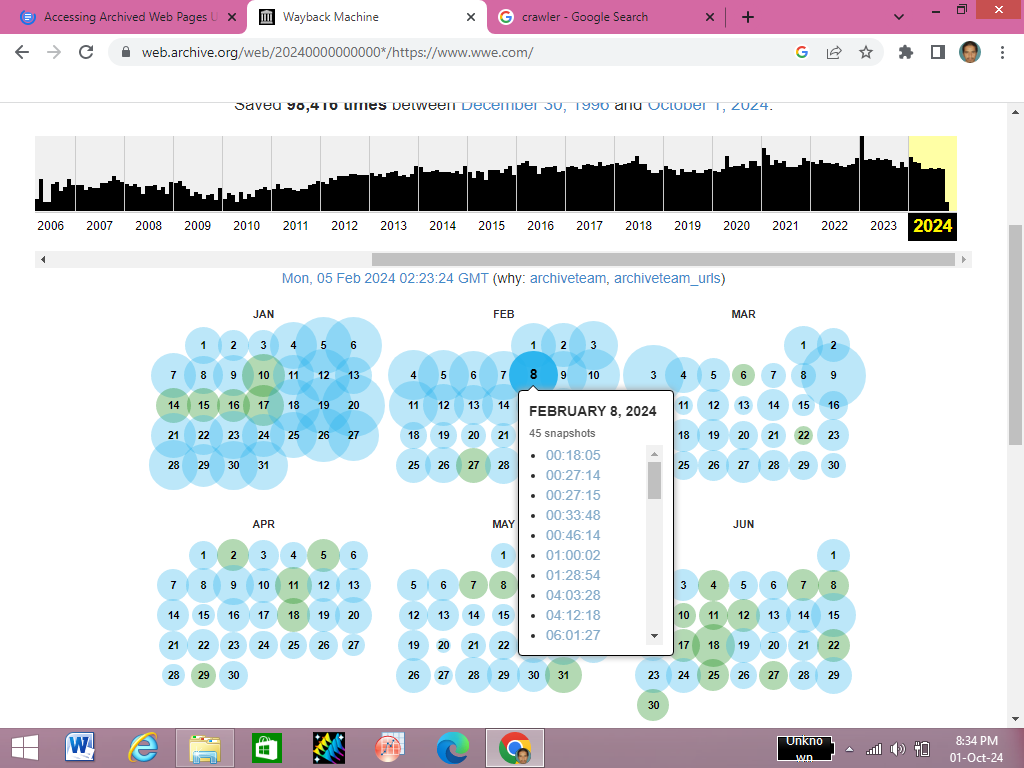
3) You will see the results showing the yearly history of the website, the calendar view is the depiction of how many times the Wayback Machine crawled the website, not how many times the site received an update.

4) Just below the calendar view (aka timeline), the history saved on a monthly basis is given. The size of the circles encircling the numbers depict the number of times snapshots were saved on that day.

5) It is important to note that each circle color represents a different meaning for example blue indicates the successful retrieval of snapshots; green indicates that the crawler was redirected; orange depicts an error that the crawler faced on the client side during retrieval; and red shows a server error faced by the crawler.
6) Click on the date of your choice and then on the clock time to see that specific snapshot. But remember, some features, like internal links, might not work due to it not being a live page.
While the Wayback Machine primarily depends on direct URLs, it can perform basic keyword searches—though with limits. These keyword queries return entire websites loosely related to the term, not deep pages where the phrase actually appears.
For instance, searching for “AI in healthcare” won’t surface every archived article with that phrase. Instead, it may lead you to archived versions of sites broadly covering AI topics in medicine.
You'll still need to manually sift through the results to find specific content. Even so, this feature remains helpful for tracking down defunct blogs, early-stage company sites, or older institutional reports no longer hosted.
How to Save Pages on the Wayback Machine
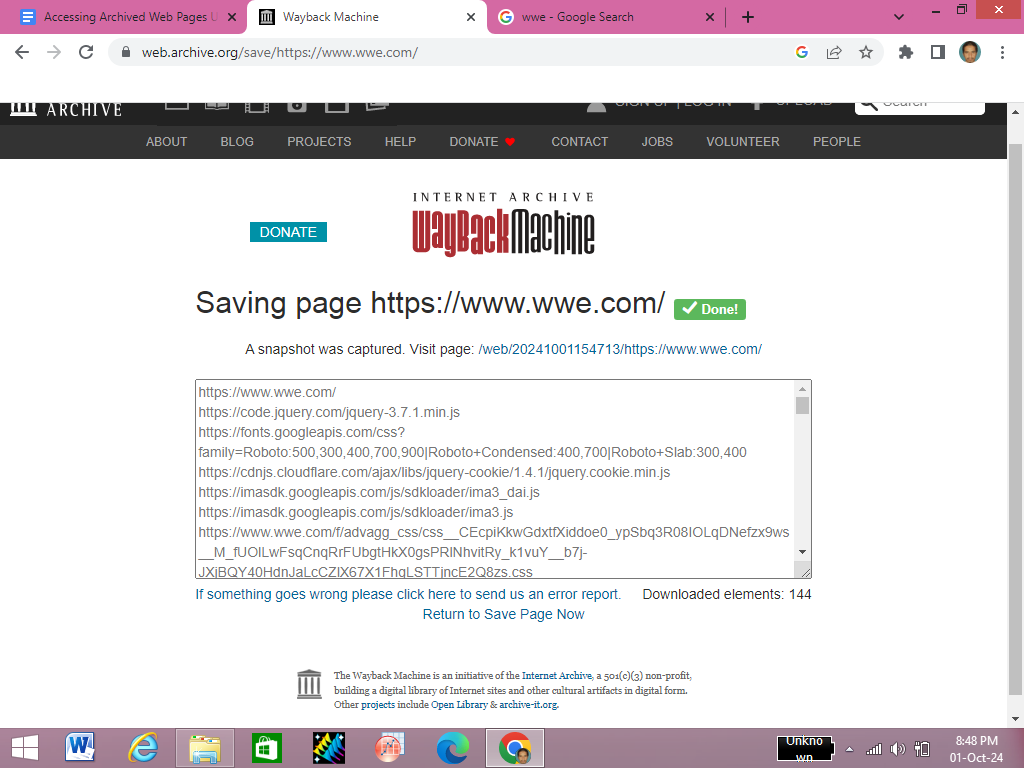
1) Go to the main page of the website. You will see save page now at the bottom right corner of the page. Or simply head over to this dedicated Save page: https://web.archive.org/save/.

2) Enter the url of the website or web page that you want to save on the website, and your page will successfully be saved in the archives.
If you have plans to frequently use the Wayback Machine, then add Wayback Machine extension to your Chrome or Firefox to conveniently interact with the website.
While the Wayback Machine remains the most extensive free archive of past web content, a few other tools can be useful in specific cases. Services like archive.today allow users to capture and permanently store snapshots of web pages, even bypassing restrictions that may block traditional crawlers. Though not as comprehensive or navigable as the Wayback Machine, such alternatives can be effective when a page isn’t available or archived elsewhere. Including both tools in your digital research toolkit ensures better access to outdated or disappearing online information.
Web archiving is no longer just a technical convenience; it’s becoming a necessity as the internet shifts faster than ever. Websites change constantly—redesigns, content edits, even entire platforms vanish—making reliable snapshots crucial for journalists, researchers, and legal experts trying to verify facts or trace digital history. Yet, this archival process is far from perfect. Many modern sites rely on complex code and dynamic content that tools like the Wayback Machine still struggle to capture fully, leaving gaps in the record. Beyond technical hurdles, there’s an ethical tension: should deleted or private information remain accessible indefinitely? The debate around digital privacy and responsible archiving is intensifying as more personal data finds its way into these archives. At the same time, archived web data is becoming a valuable asset for AI-driven research and fact-checking, highlighting its growing importance in today’s information landscape. Meanwhile, grassroots and community initiatives to preserve digital culture remind us that archiving is not just a technical task but a shared responsibility—one that will shape how future generations understand the internet’s past.
Read next:
• How to Find the Publish Date of a Website, Webpage or Article. 6 Super Hacks!
• Here's How You Can Enable Or Disable JavaScript in Your Browser
{kind=link}