
Galileo is a San Francisco based company that helps other companies build fine Large Language Model (LLM) apps. Galileo made a hallucination index that researches about different LLMs and shows which of them hallucinate when faced with multiple tasks at once. Hallucinating is a recurring problem observed in LLMs that result in inaccurate and baseless results. After the research conducted by Galileo, it was found that ChatGPT-4 hallucinates the least when it has to work on multiple tasks.
Galileo worked on different LLMs including Meta’s Llama, but it was soon revealed that many well known LLMs also cannot perform their tasks accurately without hallucinating. This keeps many enterprises from developing LLMs because they cannot work efficiently, especially in healthcare. Open AI’s GPT-4 was the only one that performed well when given tasks.
Companies use benchmarks to monitor LLMs performance, but there is no saying when they will hallucinate. To tackle this problem, co-founder of Galileo, Atindriyo Sanyal, chose 11 LLMs of all sizes and capacities and checked the performance of each of them one by one. He asked those LLMs general questions using TruthfulQA and TriviaQA to monitor their hallucination.
Galileo used its Correctness and Context Adherence metrics because they make it easy for engineers and data scientists to easily find out at what point LLMs are hallucinating. The metrics were focused on logic-based mistakes made by those LLMs.
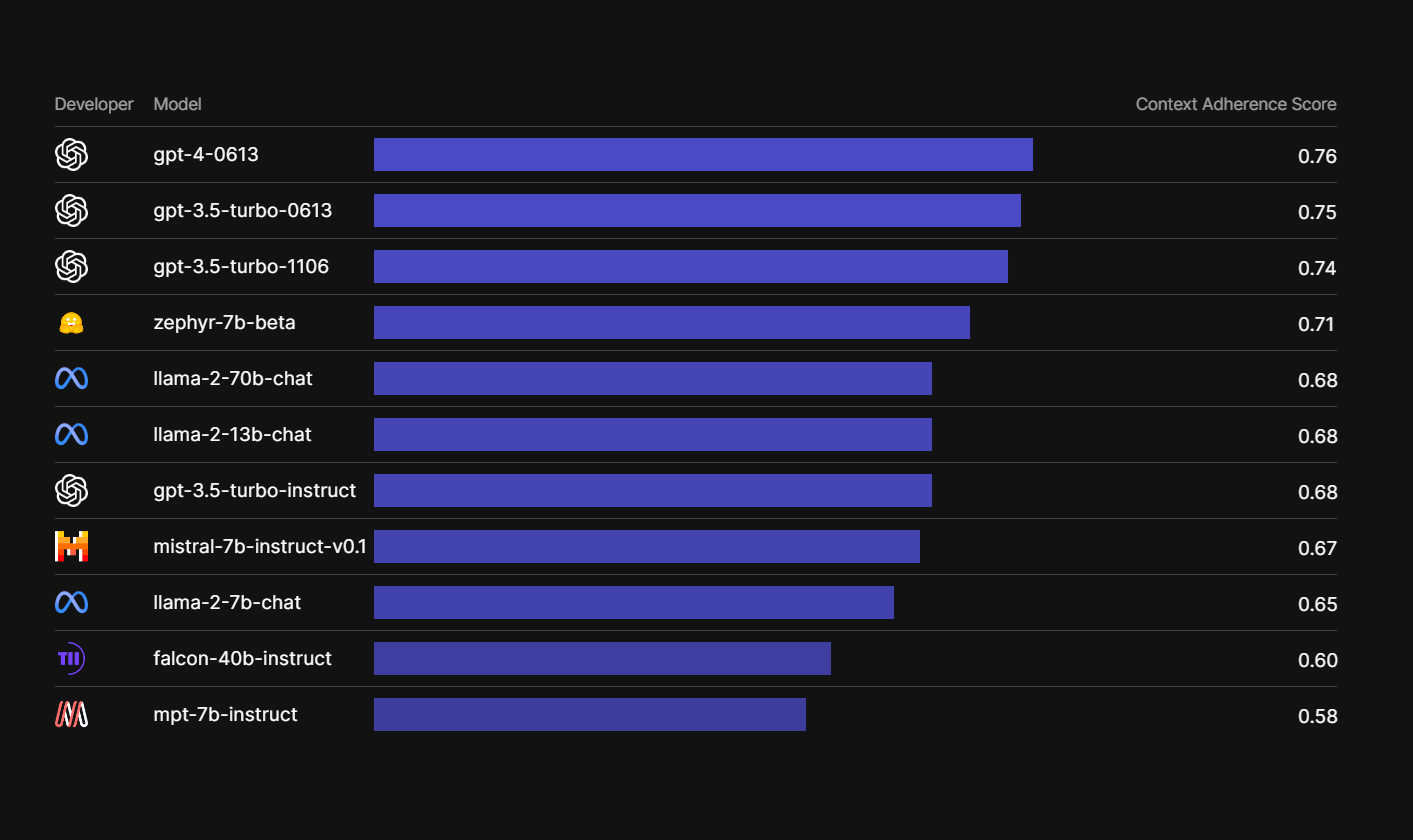
For information retrieval, GPT-4(0613) still came at the top with a 0.76 score. Zephyr-7b, a model by Hugging Face, surpassed LLama in this category with 0.71 score. Llama had 0.69 score.
The LLM that needed the most improvement and had the lowest points of 0.58 was Mosaic ML’s MPT-7b. UAE’s Falcon 40-b lies just above it with 0.60.
GPT-4(0163) was at the top for correctly generating long forms of texts like essays, articles etc. It has a score of 0.83. Llama came in second with 0.82 correctness score. These two models were the least to hallucinate when given multiple tasks. MPT-7b was the last with 0.53 score.
Read next: AI's Data Dilemma Shows Less Can Be More
Galileo worked on different LLMs including Meta’s Llama, but it was soon revealed that many well known LLMs also cannot perform their tasks accurately without hallucinating. This keeps many enterprises from developing LLMs because they cannot work efficiently, especially in healthcare. Open AI’s GPT-4 was the only one that performed well when given tasks.
Identifying LLM Hallucination– How Galileo Checked the Performance of LLMs?
Many enterprises use AI and LLMs for their businesses. But when it comes to production, LLMs aren’t always reliable because sometimes their results aren’t 100%. It is because LLMs work according to the data they are given, and not if the information is factual or accurate. When generative AIs are being developed, there are a lot of things that need to be considered like is it for general use or is it a ChatBot for enterprises?
Companies use benchmarks to monitor LLMs performance, but there is no saying when they will hallucinate. To tackle this problem, co-founder of Galileo, Atindriyo Sanyal, chose 11 LLMs of all sizes and capacities and checked the performance of each of them one by one. He asked those LLMs general questions using TruthfulQA and TriviaQA to monitor their hallucination.
Galileo used its Correctness and Context Adherence metrics because they make it easy for engineers and data scientists to easily find out at what point LLMs are hallucinating. The metrics were focused on logic-based mistakes made by those LLMs.
Correctness Score of LLMs by Galileo
After QnA with LLMs, Galileo came to a conclusion about those LLMs with a correctness score. The LLM with the highest score was GPT-4 (0613) with a 0.77 score. GPT-3.5 Turbo(1106) was just behind with 0.74 score. GPT-3.5 Turbo Instruct and GPT-3.5 Turbo(0613) both had 0.70 correctness score. After the GPT versions came Meta’s Llama-2-70b with 0.65 score. Mosaic’s ML’s MPT-7b Instruct had a 0.40 score.For information retrieval, GPT-4(0613) still came at the top with a 0.76 score. Zephyr-7b, a model by Hugging Face, surpassed LLama in this category with 0.71 score. Llama had 0.69 score.
The LLM that needed the most improvement and had the lowest points of 0.58 was Mosaic ML’s MPT-7b. UAE’s Falcon 40-b lies just above it with 0.60.
GPT-4(0163) was at the top for correctly generating long forms of texts like essays, articles etc. It has a score of 0.83. Llama came in second with 0.82 correctness score. These two models were the least to hallucinate when given multiple tasks. MPT-7b was the last with 0.53 score.
With Correctness Comes a Cost
As much as reliable ChatGPT-4 seems to be, there is still a factor that makes it less appealing to many–its pricing plan. GPT-4(0613) isn’t free to users but GPT 3.5 also serves almost the same as GPT-4 when it comes to being least hallucinated. There are also other alternatives like LLama-2-70b which is also good in its performance. Plus, it is free of cost.Read next: AI's Data Dilemma Shows Less Can Be More
{kind=link}