
The power of AI technology can never be underestimated and this new advancement from Microsoft related to voice cloning is definitely worth a glance.
The software giant was seen speaking about using artificial intelligence-powered technology to clone voices from audio clips that are just three seconds in duration. This new program has been dubbed VALL-E and it’s designed to allow for the best text-speech production.

Microsoft’s researchers highlighted that they created a feature where you can listen to nearly 60k hours of audiobook narration in English from nearly 7000 different speakers. The whole idea is to reproduce speech that sounds very human-like. And remember, this sample is almost 100s of times greater than what we usually see regular text-to-speech apps be built upon.
As recently mentioned by the Microsoft team who was seen making a mention of the new advancement on its website through the likes of demos in action, it’s actually really cool and innovative.
You’re getting the chance to clone a person’s voice through the shortest audio clips out there and you’re also being given the chance to manipulate the cloned voice to assist in saying anything you want. And if that’s not cool enough, it can go about replicating emotion in the voice and even be programmed to speak in various different styles of speaking.
We agree that voice cloning isn’t something new in this world. However, the approach taken by Microsoft really stands out as it makes it so much simpler to replicate a voice using such short snippets of audio. It only makes sense that such technology is what’s leading to cybercrime and Microsoft knows that this is a major threat.
The team mentioned how it would be possible and potentially a great idea to create something that would be able to differentiate if audio clips were produced using the VALL-E technology or not. It could really be a huge game changer we feel.
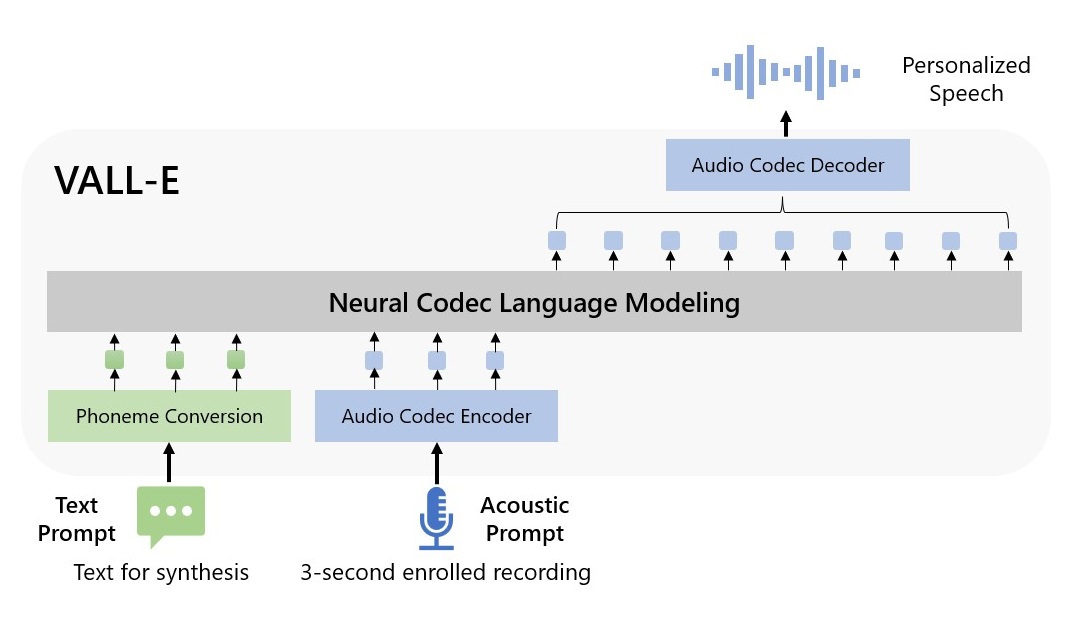
Microsoft further says that the technology deciphers audio speech in the form of discrete tokens and remakes those to talk with different types of text. The respective acoustic tokens were further conditioned to take on the likes of 3-second-long recordings and then they were used to make a final waveform using a neural codec decoder.
This type of technology is definitely not perfect but it’s diverse, innovative, and certainly unique from what has been done in this field of speech-to-text.
Read next: Microsoft to Incorporate AI Into Word to Write Documents
The software giant was seen speaking about using artificial intelligence-powered technology to clone voices from audio clips that are just three seconds in duration. This new program has been dubbed VALL-E and it’s designed to allow for the best text-speech production.
Microsoft’s researchers highlighted that they created a feature where you can listen to nearly 60k hours of audiobook narration in English from nearly 7000 different speakers. The whole idea is to reproduce speech that sounds very human-like. And remember, this sample is almost 100s of times greater than what we usually see regular text-to-speech apps be built upon.
As recently mentioned by the Microsoft team who was seen making a mention of the new advancement on its website through the likes of demos in action, it’s actually really cool and innovative.
You’re getting the chance to clone a person’s voice through the shortest audio clips out there and you’re also being given the chance to manipulate the cloned voice to assist in saying anything you want. And if that’s not cool enough, it can go about replicating emotion in the voice and even be programmed to speak in various different styles of speaking.
We agree that voice cloning isn’t something new in this world. However, the approach taken by Microsoft really stands out as it makes it so much simpler to replicate a voice using such short snippets of audio. It only makes sense that such technology is what’s leading to cybercrime and Microsoft knows that this is a major threat.
The team mentioned how it would be possible and potentially a great idea to create something that would be able to differentiate if audio clips were produced using the VALL-E technology or not. It could really be a huge game changer we feel.
Microsoft further says that the technology deciphers audio speech in the form of discrete tokens and remakes those to talk with different types of text. The respective acoustic tokens were further conditioned to take on the likes of 3-second-long recordings and then they were used to make a final waveform using a neural codec decoder.
This type of technology is definitely not perfect but it’s diverse, innovative, and certainly unique from what has been done in this field of speech-to-text.
Read next: Microsoft to Incorporate AI Into Word to Write Documents
{kind=link}